к содержанию
2.2. СТАТИСТИЧЕСКАЯ МОДЕЛЬ.
Дадим теперь формальное определение коэффициента c(a,b). Обозначим через D множество всех реальных династий длины k, то есть состоящих из k последовательных царей. Фактически за множество D нам придется взять те исторические династии, сведения о которых дошли до нас в сохранившихся исторических хрониках. Практически полный список всех таких династий мы составили на основе большого числа разнообразных хронологических таблиц, перечисленных ниже. На основе этих таблиц мы составили список всех групп из 15 последовательных царей, правивших, согласно скалигеровской хронологии, в интервале от 4000 года до н.э. до 1900 года н.э. в Европе, Средиземноморье, на Ближнем Востоке, в Египте, Азии.
Каждую летописную династию можно условно изобразить вектором в евклидовом пространстве R
k размерности k. В нашем конкретном эксперименте мы брали k=15 (см. выше). Мы будем считать две династии существенно различными, если число царей (или реальных правителей), входящих одновременно в обе эти династии, не превышает k/2, то есть половины числа членов всей династии. Две взятые наугад реальные династии могут пересекаться, поскольку каждый раз мы можем произвольно объявить того или иного царя "началом династии". Наряду с зависимыии и независимыми династиями имеются еще и "промежуточные", "нейтральные" пары династий, в которых число общих царей (или реальных правителей) превышает k/2. Ясно, что если общее число рассматриваемых династий велико, то количество промежуточных, нейтральных пар династий относительно мало. Поэтому основное внимание можно уделять зависимым и независимым парам династий.Сформулированный выше принцип малых искажений означает, что на практике, "в среднем", летописцы ошибались все-таки незначительно, то есть не очень сильно искажали реальные числовые данные.
Обсудим теперь ошибки, которые чаще всего делали летописцы при вычислении длительностей правлений древних царей. Эти три типа ошибок были выделены нами при обработке большого числа конкретных исторических текстов. Выяснилось, что именно эти ошибки чаще всего приводили к искажению реальных длительностей правлений царей.
Ошибка (1). Перестановка, путаница двух соседних царей.
Ошибка (2). Замена двух царей одним, длительность правления которого равна сумме длительностей их правлений.
Ошибка (3). Неточность в вычислении самой длительности правления. Чем больше эта длительность правления, тем большую ошибку обычно допускал летописец при ее определении.
Эти три типа ошибок можно описать и смоделировать математически. Начнем с ошибок (1) и (2). Рассмотрим какую-либо династию p=(p
1,p2,...,pk) из множества D. Вектор q=(q1,q2,...,qk) мы назовем ВИРТУАЛЬНОЙ ВАРИАЦИЕЙ вектора (династии) p, и будем обозначать его через q=vir(p), если каждая координата qi вектора c получается из координат вектора p одной из следующих двух процедур (1) и (2).(1)
Либо qi = pi (то есть координата не меняется), либо qi совпадает с одним из чисел pi-1, pi+1, то есть с одной из "соседних координат" вектора p.(2)
Либо qi = pi, либо qi совпадает с числом pi + pi+1.Ясно, что каждый такой вектор (династия) q можно рассматривать как летописную династию, получившуюся из реальной династии p в результате "ее размножения" под воздействием ошибок (1) и (2). Другими словами, мы берем каждую реальную династию p=(p
1,p2,...,pk) из списка D и применяем к ней "возмущения" (1) и (2). То есть, либо мы меняем местами два соседних числа pi и pi+1, либо заменяем какое-то число pi суммой pi + pi+1, или суммой pi-1 + pi. Для каждого номера i мы применяем указанные операции только по одному разу, то есть не рассматриваем "длинные итерации" операций на одном и том же месте i. В результате из одной династии p получается некоторое число виртуальных династий {q=vir(P)}. Количество таких виртуальных династий легко подсчитать.Таким образом, каждая "точка" из множества D "размножается" и порождает некоторое множество "виртуальных точек", ее окружающих, так сказать порождает "окрестное облако", "шаровое скопление". См. рис.3.29. Некоторые из получившихся виртуальных династий могут встретиться нам в какой-то конкретной летописи (в этом случае они будут летописными династиями), некоторые остаются всего лишь "теоретически возможными", то есть "виртуальными".

Рис. 3.29: Каждая династия p порождает некоторое множество vir(p) виртуальных династий.
Геометрически они изображаются в виде "облака", "шарового скопления",
окружающего точку p в пространстве.
Объединяя все виртуальные династии, получающиеся из всех реальных династий p, составляющих наш список D, мы получаем некоторое множество vir(D), то есть "окутывающее облако" исходного множества династий D.
Таким образом, для каждой реальной династии M, множество изображающих ее летописных династий можно представлять себе как "шаровое скопление" vir(M). Пусть теперь даны две реальные династии M и N. Если сформулированный нами принцип малых искажений верен, то шаровые скопления vir(M) и vir(N), отвечающие двум заведомо независимым, разным реальным династиям M и N, не пересекаются в пространстве R^k. То есть, они должны быть расположены достаточно далеко друг от друга. См. рис.3.30.

Рис. 3.30: "Шаровые скопления" vir(M) и vir(N), отвечающие двум заведомо независимым, размым реальным династиям
M и N, расположены "далеко друг от друга".
Пусть теперь a и b - две какие-то династии из множества vir(D), например две летописные династии. См. рис.3.31. Мы хотим ввести некоторую количественную меру близости между двумя династиями, то есть "измерить расстояние между ними", оценить - насколько они далеки друг от друга. Простейший способ был бы таким. Рассматривая обе династии как векторы в пространстве R
k, можно было бы просто взять евклидово расстояние между ними, то есть подсчитать число r(a,b), квадрат которого имеет вид:(a1 - b1)2 + ... + (ak - bk)2.
Однако численные эксперименты с конкретными летописными династиями показывают, что это расстояние не позволяет уверенно отделить друг от друга зависимые и независимые пары династий. Другими словами, такие расстояния между заведомо зависимыми летописными династиями и расстояния между заведомо независимыми летописными династиями оказываются сравнимыми друг с другом. Оказывается, они имеют "один и тот же порядок".

Рис. 3.31: Наглядное изображение длительностей правлений в двух династиях
a и b в виде графиков.
Тем более нельзя определять "похожесть" или "непохожесть" двух династий (точнее, графиков их правлений) "на глазок". Визуальная похожесть двух графиков может ни о чем не говорить. Можно привести примеры заведомо независимых династий, графики правлений которых окажутся "весьма похожими". И тем не менее никакой зависимости тут на самом деле нет. Как выяснилось, в данной проблеме визуальная близость может ввести в заблуждение. Требуется надежная количественная оценка, устраняющая зыбкие субъективные соображения вроде "похожи",
"не похожи".Итак, задача состоит в том, чтобы выяснить - существует ли вообще такая естественная мера близости (на множестве всех виртуальных династий), которая позволила бы уверенно отделить зависимые династии от независимых. То есть, чтобы "расстояние" между заведомо зависимыми династиями было "мало", а "расстояние" между заведомо независимыми династиями было "велико". Причем, требуется, чтобы эти "малые" и "большие" значения существенно отличались бы друг от друга, например, чтобы они были отделены одним или несколькими порядками.
Оказывается, такая мера близости, то есть "расстояние между династиями", действительно существует. К описанию такого коэффициента c(a,b) мы сейчас и перейдем.
Итак, мы построили в пространстве R
15 некоторое множество династий D. Были смоделированы две наиболее типичные ошибки, делавшиеся летописцами. Каждая династия из множества D была подвергнута возмущениям типов (1) и (2). При этом каждая точка из D размножилась в несколько точек, что привело к увеличению множества. Получившееся множество мы обозначали через vir(D). Оказалось, что множество vir(D) состоит примерно из 15∙1011 точек.Будем считать "династический вектор a" случайным вектором в R
k, пробегающим множество vir(D). Тогда по множеству vir(D) мы можем построить функцию z плотности вероятностей. Для этого все пространство R15 было разбито на стандартные кубы достаточно малого размера так, чтобы ни одна точка из множества vir(D) не попала на границу какого-либо куба. Если x - внутренняя точка куба, то положим
| z(x) = |
число точек из множества vir(D), попавших в куб общее количество точек в множестве vir(D) |
Ясно, что для точки x, лежащей на границе какого-либо куба, можно считать, что z(x)=0. Функция z(x) достигает максимума в области, где сосредоточено особенно много династий из множества vir(D), и падает до нуля там, где точек из множества vir(D) нет. См.рис.3.32. Тем самым, график функции z(x) наглядно показывает, как именно распределено множество династий vir(D) по пространству R
k. Другими словами, где это множество "густое", "плотное", а где оно разрежено.
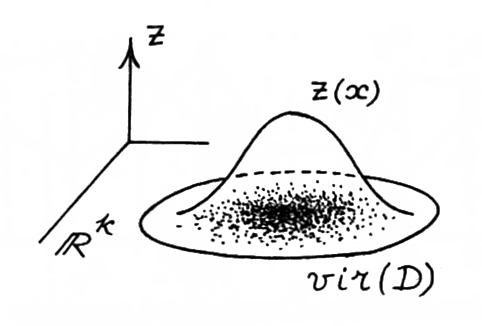
Рис. 3.32: Функция плотности, показывающая распределение точек множества
Пусть теперь нам заданы две династии a=(a
1,...ak) и b=(b1,...,bk), и мы хотим оценить - насколько они близки или далеки. Построим k-мерный параллелепипед P'(a,b) с центром в точке a, имеющий в качестве диагонали вектор a-b. См. рис.3.33. Если спроектировать параллелепипед P'(a,b) на i-ю координатную ось, то получится отрезок с концами[ai - |ai - bi|, ai + |ai - bi|].

Рис. 3.33: Параллелепипеды P'(a,b) и P(a,b).
В качестве "предварительного коэффициента" c'(a,b) мы возьмем число
| c'(a,b) = |
число точек из множества vir(D), попавших в P'(a,b) общее число точек в множестве vir(D) |
Ясно, что число c'(a,b) является интегралом функции плотности z(x) по параллелепепиду P'(a,b).
Смысл этого "предварительного коэффициента" c'(a,b) ясен. Династии, то есть векторы из vir(D), попавшие в параллелепипед P'(a,b), естественно назвать "похожими" на династии a и b. В самом деле, каждая из таких династий удалена от династии a не более чем от династии a удалена династия b. Следовательно, в качестве меры близости двух династий a и b, мы берем долю династий, "похожих" на a и b, в множестве всех династий vir(D).
Однако такой коэффициент c'(a,b) пока недостаточно хорош, поскольку он никак не учитывает то обстоятельство, что летописцы определяли длительность правлений царей с какой-то ошибкой, причем обычно тем большей, чем дольше длительность правления. Другими словами, нам нужно учесть ошибку летописцев (3), обсужденную выше.
Перейдем к моделированию ошибки (3). Пусть T - это длительность правления. Ясно, что длительность правления можно рассматривать как случайную величину, определенную на "множестве всех царей". Обозначим через g(T) число царей, правивших T лет. В работе [375] я экспериментально вычислил эту гистограмму частот g(T) (плотность распределения указанной случайной величины) на основе данных, приведенных в "Хронологических Таблицах" Ж.Блера [20]. Положим h(T)=1/g(T) и назовем h(T) функцией ошибок (летописцев). Ошибка h(T) в определении длительности T тем больше, чем с меньшей вероятностью случайная величина, - то есть длительность правления, - принимает значение T. Другими словами, небольшие, "короткие" длительности правлений царей лучше поддаются вычислению. Здесь летописец ошибается незначительно. Напротив, большие длительности правлений царей, встречающиеся довольно редко, летописец обычно вычисляет с существенной ошибкой. Чем больше длительность правления, тем большую ошибку он может совершить.
Функция ошибок h(T) для указанной плотности вероятностей случайной величины (длительности правления) была определена экспериментально [375], с.115. Разобьем отрезок [0,100] целочисленной оси T на десять отрезков одинаковой длины, а именно:
[0,9], [10,19], [20,29], [30,39], ... [90,99].Тогда оказывается, что:
h(T)=2, если T изменяется от 0 до 19,
h(T)=3, если T изменяется от 20 до 29,
h(T)=5([T/10]-1), если T изменяется от 30 до 100.
Здесь через [s] обозначена целая часть числа s. См.рис.3.34.

Рис. 3.34: Экспериментально вычисленная "функция ошибок летописцев".
Учтем теперь ошибки летописцев при построении "окрестности" точки a. Для этого расширим параллелепипед P'(a,b) до бо'льшего параллелепипеда P(a,b), центром которого по-прежнему является точка a, и ортогональными проекциями на координатные оси являются отрезки с концами
[ai - |ai - bi| + h(ai), ai + |ai - bi| + h(ai)].
Ясно, что параллелепипед P'(a,b) целиком лежит внутри большого параллелепипеда P(a,b). См. рис.3.33. Диагональю этого большого параллелепипеда является вектор a
– b + h(a), где вектор h(a) выглядит так: h(a)=(h(a1),...,h(ak)). Его можно назвать вектором ошибок летописцев.Итак, мы смоделировали все три основные ошибки, делавшиеся летописцами при подсчете ими длительностей правлений царей. В качестве окончательного коэффициента c(a,b), измеряющего близость или удаленность друг от друга двух династий a и b, мы возьмем следующее число:
| c(a,b) = |
число точек из множества vir(D), попавших в P(a,b) общее количество точек в множестве vir(D) |
Ясно, что число c(a,b) является интегралом функции плотности z(x) по параллелепепиду P(a,b). На рис.3.35 число c(a,b) условно изображается объемом призмы, имеющей в качестве основания параллелеипед P(a,b), и ограниченной сверху графиком функции z. Число c(a,b) можно, при желании, интерпретировать как вероятность того, что случайный "династический вектор", распределенный в пространстве R
k с функцией плотности z, оказался на расстоянии от точки a, не превышающем расстояния между точками a и b, с учетом ошибки h(a). Другими словами, случайный "династический" вектор, распределенный с функцией плотности z, попал в окрестность P(a,b) точки a, имеющую "радиус" a – b + h(a).

Рис. 3.34: Экспериментально вычисленная "функция ошибок летописцев".
Из предыдущего видно, что роль династий a и b при подсчете коэффициента c(a,b) неодинакова. Династия a была помещена в центр параллелеипеда P(a,b), а династия b определяла его диагональ. Конечно, можно было "уравнять в правах" династии a и b, поступив по аналогии с предыдущим коэффициентом p(X,Y). То есть, можно поменять местами династии a и b, вычислить коэффициент c(b,a), а затем взять среднее арифметическое чисел c(a,b) и c(b,a). Мы этого не делали по двум причинам. Во-первых, как показали конкретные эксперименты, замена коэффициента c(a,b) на его "симметризацию" фактически не меняет получающихся результатов. Во-вторых, в некоторых случаях династии a и b действительно могут быть неравноправными в том смысле, что одна из них может быть оригиналом, а вторая - всего лишь ее дубликатом, фантомным отражением. В этом случае естественно помещать в центр параллелепипеда династию a, претендующую на роль оригинала, а "фантомное отражение" b рассматривать как "возмущение
" династии a. Возникающие различия между коэффициентами c(a,b) и c(b,a) хотя и невелики, но могут послужить полезным материалом для дальнейших, более тонких исследований, которых мы пока не проводили.